| 作者 | 原文链接 | 版本 |
|---|---|---|
| apple/swift | Swift Compiler Performance | b23b335 |
本文档是一份关于理解、诊断并报告 Swift 编译器编译性能问题的指南。即:编译器编译代码的速度,而非代码运行的速度。
虽然本指南较长,但内容其实相当简单。在很大程度上,性能分析需要耐住性子、考虑周全且坚持不懈,谨小慎微且始终如一地测量,并逐步消除噪音且专注于一个信号。
影响编译性能的流程与因素概述
本节从较为宏观的角度论述关于编译器在运行时所做的工作,不仅包括显而易见的「编译」,以及影响编译器耗时的主要因素。
当我们使用 Xcode 或在命令行中编译或运行 Swift 程序时,通常将调用 swift 或 swiftc(后者是前者的符号链接),这是一个根据不同参数能够以显著不同的方式运行的程序。
虽然它可以直接编译或运行代码,但它通常会反过来运行一个或多个 swift 或 swiftc 副本作为子进程。在典型的批量编译中,swiftc 的第一个副本将被作为驱动(Driver)进程运行,之后它将在进程树中运行一些所谓的前端(Frontend)子进程。当我们要理解 Swift 编译时,我们必须清楚地了解哪些进程在运行,以及它们在做什么:
- 驱动:子进程树中的顶层
swiftc进程。负责决定哪些文件需要被编译或重新编译,以及运行子进程。子进程即所谓的作业(Jobs),它们运行编译和链接步骤。通常在运行时,驱动是空闲的,等待其它子进程完成。 - 前端作业(Frontend Jobs):由驱动启动的子进程,运行
swift -frontend ...、运行编译、PCH 文件生成、模块合并等。这些作业大量增加了编译开销。 - 其它作业(Other Jobs):由驱动启动的子进程,运行
ld、swift -modulewrap、swift-autolink-extract、dsymutil、dwarfdump,以及涉及收尾前端已完成作业等类似工具。其中一些也是swift程序,但它们并非「运行前端作业」,因此将会有完全不同的分析。
这些运行的一系列作业以及它们的耗时方式高度依赖于编译模式。有关编译性能的这些模式信息将在下一节中详述;关于驱动的更多详细信息,请参阅驱动文档、以及有关驱动内部和驱动可解析输出的文档。
在下一节讨论完编译模式之后,我们还将涉及可能在没有明显热点(Hotspot)出现的情况下,所发生的工作量大幅变化,这将分别从懒惰策略(Laziness Strategies)与近似两个角度论述。
编译模式
编译器有许多不同的选项可以控制驱动和前端作业,但导致行为上最显著差异的两个维度通常被称作模式(Modes)。因此当我们着眼于编译时,弄清楚 swiftc 的运行模式便十分重要,以及要时常对每个模式进行独立的分析。这些重要的模式如下:
- 主文件(Primary-File)与全模块(Whole-Module):不同模式取决于驱动是否使用
-wmo(又名-whole-module-optimization)参数运行。- 批量(Batch)与单文件(Single-File)主文件模式:随着 Swift 4.2 正式版中加入了新的批量模式,这种区分完善了主文件模式的行为。批量模式减小了主文件模式的众多开销,并最终成为运行主文件模式的默认方式,但在此之前开启批量模式需传递
-enable-batch-mode参数。
- 批量(Batch)与单文件(Single-File)主文件模式:随着 Swift 4.2 正式版中加入了新的批量模式,这种区分完善了主文件模式的行为。批量模式减小了主文件模式的众多开销,并最终成为运行主文件模式的默认方式,但在此之前开启批量模式需传递
- 优化(Optimizing)与无优化(Non-Optimizing):不同模式取决于驱动(以及因此每个前端)是否使用
-O、-Osize、-Ounchecked(每个参数代表开启一个或多个优化选项),或默认(无优化),即等同于-Onone和-Oplayground。
当我们使用 Xcode 或用 xcodebuild 构建程序时,通常有一个配置参数会同时切换这两种模式。也就是说,典型的代码有两种配置:
- Debug:即结合主文件模式与
-Onone - Release:即结合 WMO 模式与
-O
这些参数均可单独更改,编译器的耗时也将根据设置而有所不同,因此这值得我们更详细地了解这两个维度。
主文件(带与不带批处理)与 WMO
这是编译器行为中最重要的变量,因此这值得我们彻底搞清楚:
- 在主文件模式下,驱动将它要运行的工作分配给多个前端进程,每个前端完成后将得出部分结果,驱动在所有前端完成后合并这些结果。每个前端作业本身读取模块中的全部文件,专注于其编译时读取部分中的一个或多个主要文件,并根据需要从模块中懒分析其它引用定义。该模式有两种子模式:
- 在单文件子模式下,编译器对每个文件运行一个前端作业,且每个作业只有一个主文件。
- 在批处理子模式下,编译器对每个 CPU 运行一个前端作业,将模块文件中等大的「批处理」标示为主文件。
- 在全模块(WMO)模式下,驱动只为整个模块运行一个前端作业。该前端一次性读取模块中的全部文件,并一次性全部编译。
举个例子:如果我们有一个包含 100 个文件的模块:
- 运行
swiftc *.swift将以单文件模式编译,因此将运行 100 个前端子进程,每个子进程将解析全部 100 个输入(总共 10,000 次解析),最后每个子进程将(并行)编译单个主文件的定义。 - 运行
swiftc -enable-batch-mode *.swift将以批处理模式编译,因此在一个拥有 4 个 CPU 的系统上将运行 4 个前端子进程,每个子进程将解析全部 100 个输入(总共 400 次解析),最后每个子进程将(并行)编译 25 个主文件定义(每个进程中模块数的四分之一)。 - 运行
swiftc -wmo *.swift将以全模块模式编译,因此将运行一个前端子进程,并一次性读取全部 100 个文件(总共 100 次解析),最后按顺序(串行)编译全部文件的定义。
为什么存在多种模式?因为它们各自有不同的优点与不足;没有一种模式是完美的:
- 主文件模式的优点是,驱动可以通过仅为已过时的文件运行前端从而进行增量编译(Incremental Compilation),以及利用多核并行运行多个前端作业。其不足是每个前端作业必须在专注于其感兴趣的主文件之前读取模块中的全部源文件,这意味着一部分前端作业将按其数量的平方次完成。虽然通常这一部分作业相对较小且快,但由于是平方级就很容易出现问题。批量模式的增加就是为了消除初期作业的平方次递增。
- WMO 模式的优点是,当确定着眼于整个模块时才会进行优化,并且避免了主文件模式初期阶段的平方次作业。缺点是其总是需要重新构建一切,而且不能很好地利用并行(但至少在 LLVM IR 代码生成之前,其总是多线程的)。
全模块模式确实开启了主文件模式编译时无法实现的一系列优化。尤其在含有大量私有死代码的模块中,全模块模式能够更早地消除死代码,并避免不必要的编译工作,从而实现更精简的输出和更迅速的编译。
因此有可能的是,在某些特定情况下(例如可用的并行有限 / 许多模块已由并行构建),禁用优化的全模块构建可能比批处理主文件模式消耗更少的时间。但这种情况取决于许多因素,鲜有显著优势,而且由于完全放弃了对于增量编译的支持,因此这并非一种建议的配置。
优化量
本文档并不会详细概述编译器体系结构,但牢记编译器以 3 种主要表现形式处理在内存中的 Swift 代码是十分重要的。因此,在概念上可以被分为 3 个主要阶段,其中后 2 个阶段根据优化模式不同而行为不同:
- AST(抽象语法树):这是最接近于源代码的表现形式(定义在
lib/AST目录下),产生自 Swift 源代码、Swift 模块和 Clang 模块(分别定义在lib/Parse、lib/Serialization和lib/ClangImporter目录下),并在编译初期由解析、类型检查、以及高级语义函数解释。 - SIL(Swift 中间语言):这是一种专用于 Swift 编译器的形式,比 AST 更底层也更易于理解。但仍然较于如 LLVM 这样面向机器的表现形式更加上层且更特定于 Swift。其定义在
lib/SIL中,产生自lib/SILGen中的代码,并由lib/SILOptimizer中的代码选择性优化。 - LLVM IR(低级虚拟机的中间表示法):这一种抽象表示将编译至机器语言的形式。其不包含任何特定于 Swift 的知识,而是一种由 Swift 编译器从 SIL(位于
lib/IRGen)中生成的形式,然后作为输入到达 LLVM 后端,LLVM 后端是 Swift 编译依赖的一个库。LLVM 在降级至机器码之前拥有自身适用于 LLVM IR 的选择性优化。
当在优化模式下运行 Swift 编译器时,许多 SIL 和 LLVM 优化被开启,使得(在每个前端作业中)编译的这些阶段显著消耗更多的时间与内存。当在无优化模式下,SIL 和 LLVM IR 仍会在流程中被制造和消费,但由于只作为降级部分,应用的「简单」优化相对较少。
另外,IRGen 和 LLVM 阶段能够通过在每个前端作业中使用多线程以并行运行(通常也是并行运行),由 -num-threads 标志控制。然而该选项只应用于较后期的阶段,因为 AST 和 SIL 相关的阶段从不以多线程运行。
在不同的优化模式之间,AST 表现形式(尤其是:导入、解析、和类型检查 AST)下的工作量并无不同。然而,不同项目之间、以及对代码进行看似微笑的改动之间,工作量却大相径庭,这取决于前端所能够发挥的懒惰程度。
工作量的可变性、近似性、与懒惰性
- FIX
虽然导致编译缓慢的一些原因有明确的热点(我们很快就会了解到),但在性能分析时要牢记的最终的一件事情是:编译器试图以不同的方式懒惰,而这种懒惰并不总是奏效:其由确定的近似和假设驱动,而这些经常会在比严格要求下更多的工作量上出错。
懒惰中的失败结果并不总是在分析中可见:相反,其是通过普遍均一的分析做了「太多一起的工作」的表现。特别是发生这种情况的两个领域 —— 需要进行重大、持续改进的领域 —— 即增量编译和懒惰决议。
增量编译
正如主文件模式一节中所提到的,驱动具有增量模式,可用于尝试完全避免前端作业的运行。当成功时,这是节省时间的可能性中最有效的形式:一个根本不运行的进程是最快的。
不幸的是,关于一个文件何时「需要重新编译」的判断,其本身由归纳文件之间依赖关系的辅助数据结构驱动,这个数据结构必然是一个保守的近似值。这个近似值小于实际的值,因此驱动通常运行的前端作业要比其应当运行的数量更多。
懒惰决议
Swift 源代码文件中包含的名称引用了封装文件之外的定义,且经常是封装模块之外的定义。这些「外部」定义从两个非常不同的位置(均称作「模块」)进行懒惰决议:
- C/ObjC 模块,由 Clang 导入器提供
- 序列化 Swift 模块
尽管存在差异,但两种类型的模块均在 Swift 编译器中以一种关键的方式支持懒惰:它们均为索引二进制文件格式,允许按名称加载单一定义,而无需加载模块中的全部内容。
当 Swift 编译器设法懒惰并限制从模块加载的定义数量时,其可以非常快速;文件格式支持非常低成本的访问。但往往 Swift 编译器中的逻辑对于利用这种潜在的懒惰有些不必要的保守,因此加载了比其应当加载的定义更多。
总结:编译性能的高层概览
Swift 编译性能至少由以下参数而显著不同:
- WMO 与主文件(非 WMO)模式,包含批处理
- 优化与无优化模式
- 已避免的工作量增量(若在非 WMO 模式)
- 懒惰加载外部定义的数量
当触及 Swift 编译性能时,重要的是要意识到这些参数并牢记于心,因为它们往往会框定我们正在分析的问题:改变一个(或在项目中影响它们的任何因素)将可能完全改变结果曲线。
已知问题方面
在我们已知编译器有空间改进性能、提升效率的方面上,值得在这一主题之上去寻找现有 Bug,值得找到了解这些方面的现有团队成员,并尝试将我们发现的问题与现有一些改进策略和计划相关联:
- 增量模式过于近似,运行太多子进程。
- 在平方阶段,太多被引用(非主文件)的定义被过多地类型检查。
- 表达式类型推断解决约束低效,有时可能超线性甚至指数级。
- 在分析阶段,SIL 优化周期性无法缓存重复的子问题,将导致超线性减速。
- 一些 SIL 到 IR 的降级(例如大值类型)可能产生过多的 LLVM IR,增加 LLVM 中的耗时。
(子系统专家:请在此添加更多关注领域)
如何诊断编译性能问题
编译器性能分析分为两大类工作,取决于我们尝试做什么:
- 隔离回归
- 寻找需要普遍改进的方面
在任何情况下,熟悉我们所掌握的几种工具和编译器选项至关重要。如果你已经了解所有这些工具,可以跳过该部分。
工具与选项
沿途,我们将使用几种工具。主要分为 5 大类:
- 分析器
- 编译器内置诊断选项(定时器、计数器)
- 进一步分析诊断输出的后期工具
- 通用化分析编译器输出产物的工具
- 最小化回归范围或测试用例的工具
分析器
性能分析的基本工具是分析器,而我们将至少需要学习一款分析器来完成这项工作。我们主要使用的两款分析器为 macOS 上的 Instruments.app 和 Linux 上的 perf(1)。这两款软件均免费提供,且功能异常强大;本文档仅涉及它们的基本功能。
Instruments.app
Instruments 是 macOS 上作为 Xcode 一部分所附带的一款工具。其包含各种分析服务的图形化与批处理接口,更多文档可参阅这里。
我们使用 Instruments.app 的主要方式是在「计数器」模式下,记录和分析 swiftc 的单次运行情况。我们也会将其当作正常的应用程序,在简易的按钮交互模式下使用。虽然我们可以在命令行下以批处理模式运行 Instruments,但批处理界面不如交互式应用程序更加可靠,而且经常会导致锁定或无法收集数据。
同样,我们应当确保尽可能多的应用程序(尤其那些自带调试信息)被关闭,因此 Instruments 可以尽可能少的符号化额外的材料。由于其以非常高的分辨率收集整个系统的配置文件,所以我们想要通过在一台安静的机器上执行兴趣之外的任务,来让整个过程更加简单。
做好准备,请按以下步骤继续:
- 打开
Xcode.app - 点击
Xcode=>Open Developer Tool=>Instruments(当其已经打开后,我们可能会将Instruments.app固定在 Dock 中以简单化访问) - 选择
Counter分析模版 - 打开终端,并准备运行测试用例
- 切换回
Instruments.app - 点击仪表面板顶部左侧红色
record按钮 - 快速切换终端,运行我们想要分析的测试用例,并当结束时切换回
Instruments.app,并点击停止按钮
就是这样!我们应当已经为分析做好准备。
理想情况下,我们将希望遇到如下情况:
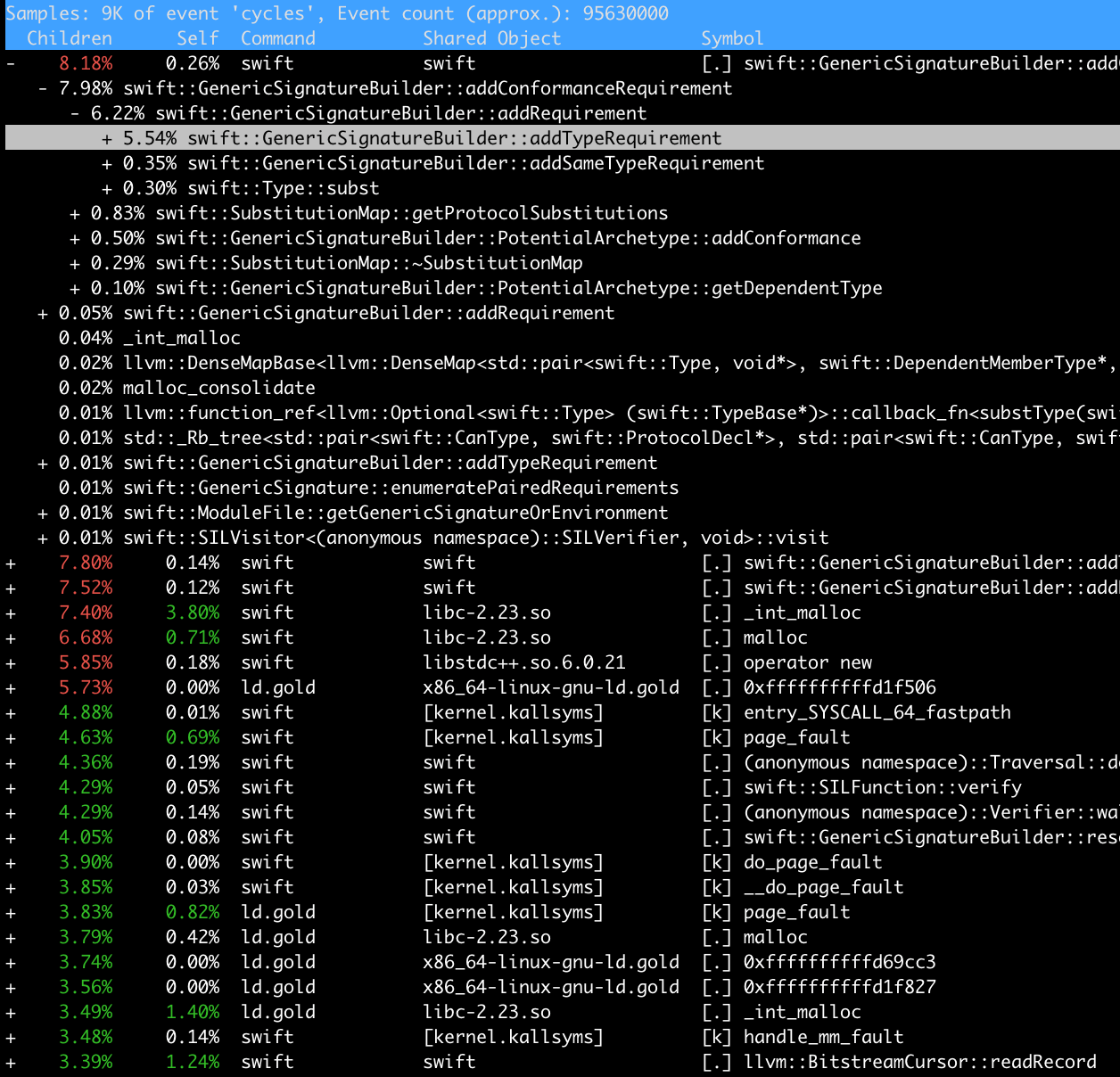
在主面板中,我们能看到一组按时间排序的进程和调用帧样本,也可以通过在窗口下方的 Input Filter 区域输入 swift 来过滤只显示 swift 进程。主面板中的每一行都可以通过点击起左侧三角形来展开,被调函数将作为缩进化的子帧展示。
如果将鼠标指针悬停在特定的 swift 进程相对应的行上,我们将会看到该行右侧的灰色圆圈内有一个小箭头。点击这个小箭头,Instruments 将把主面板的焦点转移到该流程的子树上(并相应地重新计算时间百分比)。一旦关注到了一个特定的 swift 进程,我们就可以开始查看其单独的栈帧配置。
在主面板右侧的面板中,我们可以看到主面板当前选中行的 Heaviest Stack Trace(重量级堆栈跟踪)。如果我们点击该栈上的一个帧,主面板将自动展开从当前帧到点击帧之间的每一级。例如,点击第 11 帧 swift::ModuleFile::getModule 将展开主面板展示如以下内容:
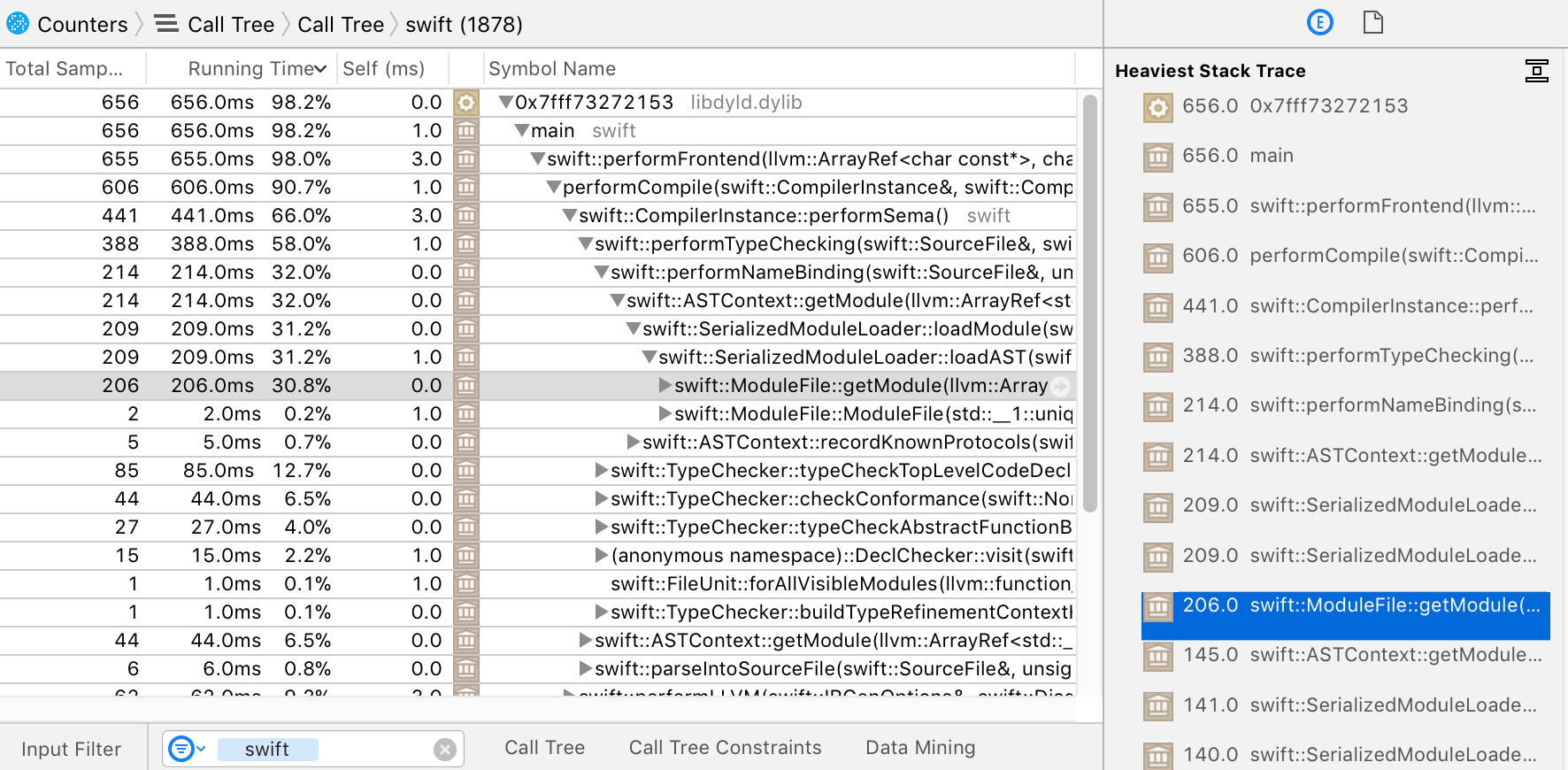
通过扩展和收缩栈树中的节点来点击一个配置时,我们将很快感受到程序耗时之处。主界面的每一行展示了累计的样本数和其子树(包含所有子树的子树)的运行时长,以及其自身特定帧的 Self 时间。
在上述例子中,能够很清晰地得出编译器在 Sema 阶段消耗了 66% 的时间,并且其中最重量级的栈是用于反序列化外部定义(这与之前所提到的已知问题方面相符)。
如果想要保留我们浏览分析时看到的记录,可以展开和折叠帧直到看到一个有意义的模式,然后选择显示的一组栈帧,拷贝为文本(照例使用 ⌘-C)并粘贴到文本文件中;拷贝后的文本将插入空格缩进以保持栈结构的可读性。
如果我们有两个分析希望进行对比,Instruments 确实有一个模式可以直接在分析中比较不同,但当分析收集自不同的二进制时便不起作用。因此当为了对比不同的 swift 编译器时,我们通常不得不手动比较。
Perf
Perf 是一个运行于命令行的 Linux 分析器。在许多 Linux 发行版中,其包含在被命名为 linux-tools 的包中。它小巧、迅速、健壮、灵活,并且很容易脚本化;主要缺点是缺乏任何形式的 GUI 且只能运行于 Linux,所以我们无法使用它来诊断需要 macOS/iOS 框架或运行于 xcodebuild 下的构建中的问题。
Perf 在内核 Wiki 和 Brendan Gregg 的网站上均有文档。
使用 perf 需要访问硬件性能计数器,所以我们无法在大多数虚拟机上使用(除非它们虚拟化访问性能计数器)。此外,我们需要 root 权限访问来使用内核的分析接口。
最简单的 perf 使用方法就是在 perf stat 下运行我们的命令。这将给予高级别性能计数器,包括指令执行计数,这是总执行消耗的相对稳定近似值,并且在进行二分法时,这通常足以找出一个回归(如下):
$ perf stat swiftc t.swift
Performance counter stats for 'swiftc t.swift':
2140.543052 task-clock (msec) # 0.966 CPUs utilized
17 context-switches # 0.008 K/sec
6 cpu-migrations # 0.003 K/sec
52,084 page-faults # 0.024 M/sec
5,373,530,212 cycles # 2.510 GHz
9,709,304,679 instructions # 1.81 insn per cycle
1,812,011,233 branches # 846.519 M/sec
22,026,587 branch-misses # 1.22% of all branches
2.216754787 seconds time elapsed
perf 提供了相对稳定和精确的开销测量,意味着当执行其它性能分析任务时,其可以被封装为一个有用的子程序,例如二分(见 git bisect 一节)或削弱(见 creduce 一节)。如下的 Shell 函数便十分有用:
count_instructions() {
perf stat -x , --log-fd 3 \
-e instructions -r 10 "$@" \
3>&1 2>/dev/null 1>&2 | cut -d , -f 1
}
为了通过 perf 获得完整的分析 —— 。
$ perf record -e cycles -c 10000 --call-graph=lbr swiftc t.swift
[ perf record: Woken up 5 times to write data ]
[ perf record: Captured and wrote 1.676 MB perf.data (9731 samples) ]